Fully connected layer with activation, using column-major matrices. More...
Public Member Functions | |
| CudaDenseLayer (int in, int out, ActivationType act) | |
| Construct a dense layer. More... | |
| int | in () const |
| Input dimension. More... | |
| int | out () const |
| Output dimension. More... | |
| size_t | params_size () const |
| Total parameter count (weights + bias) More... | |
| size_t | weights_size () const |
| Weights parameter count. More... | |
| size_t | bias_size () const |
| Bias parameter count. More... | |
| void | bind (CudaScalar *params, CudaScalar *grads) |
| Bind parameter and gradient buffers. More... | |
| CudaScalar | init_stddev () const |
| Recommended stddev for weight initialization. More... | |
| void | forward (CublasHandle &handle, const CudaScalar *input, int batch, CudaScalar *output) |
| Forward pass: Z = W*X + b, A = act(Z) More... | |
| void | backward (CublasHandle &handle, const CudaScalar *input, const CudaScalar *output, CudaScalar *next_grad, int batch, CudaScalar *prev_grad) |
| Backward pass: compute dW, db, and optionally dX. More... | |
| const CudaScalar * | params_ptr () const |
| Raw parameter pointer for this layer. More... | |
| const CudaScalar * | grads_ptr () const |
| Raw gradient pointer for this layer. More... | |
Detailed Description
Fully connected layer with activation, using column-major matrices.
Constructor & Destructor Documentation
◆ CudaDenseLayer()
|
inline |
Construct a dense layer.
- Parameters
-
in Input dimension out Output dimension act Activation type
Member Function Documentation
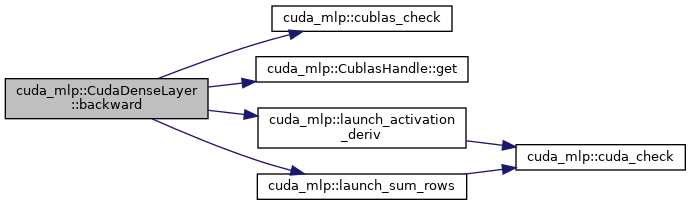
◆ backward()
|
inline |
Backward pass: compute dW, db, and optionally dX.
- Parameters
-
handle cuBLAS handle input Input activations output Output activations next_grad Gradient w.r.t. output (out x batch), updated in-place batch Batch size prev_grad Optional gradient w.r.t. input (in x batch)
Here is the call graph for this function:
◆ bias_size()
|
inline |
Bias parameter count.
◆ bind()
|
inline |
Bind parameter and gradient buffers.
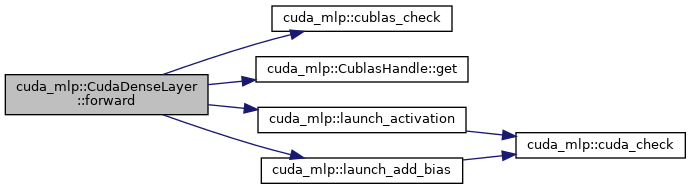
◆ forward()
|
inline |
Forward pass: Z = W*X + b, A = act(Z)
- Parameters
-
handle cuBLAS handle input Input matrix (in x batch) batch Batch size output Output matrix (out x batch)
Here is the call graph for this function:
◆ grads_ptr()
|
inline |
Raw gradient pointer for this layer.
◆ in()
|
inline |
Input dimension.
◆ init_stddev()
|
inline |
Recommended stddev for weight initialization.
Here is the call graph for this function:

◆ out()
|
inline |
Output dimension.
◆ params_ptr()
|
inline |
Raw parameter pointer for this layer.
◆ params_size()
|
inline |
Total parameter count (weights + bias)
◆ weights_size()
|
inline |
Weights parameter count.
The documentation for this class was generated from the following file:
- src/cuda/layer.cuh